Kooperation: C. Steinborn (FU), U. Grimmer, G. Nakhaeizadeh, H. Kauderer (Forschungszentrum Daimler-Benz AG, Ulm)
Beschreibung der Forschungsarbeit:
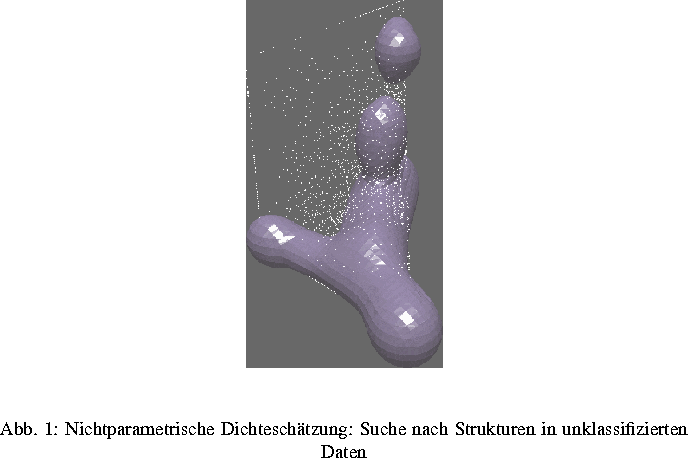
Im allgemeinen werden der nichtparametrischen Dichteschätzung geeignete Projektionstechniken vorangestellt, die möglichst viele Informationen des hochdimensionalen Beobachtungsraumes in einen niedrigdimensionalen Unterraum abbilden. Die adaptive Clusteranalyse kann die zur Struktursuche geeigneten Projektionsparameter berechnen.
Die Software wurde auf der Grundlage der OpenGL-basierten Toolbox gltools
des WIAS entwickelt. Es können nichtparametrische Dichteschätzungen von
unklassifizierten oder gruppierten Daten angezeigt werden. Interaktive
Aktionen wie z. B. Drehungen und intuitive Bedienungsweisen erlauben eine
schnelle Information des
Benutzers über die Konturen der Punktwolken.
Beim L1-Algorithmus ist der Repräsentant eines Clusters aus den Medianen der einzelnen Variablen zu bestimmen. Durch eine Modifikation des quick-sort-Algorithmus (C. A. R. Hoare) gelingt es, den Median mit linearem Aufwand von O(nK) zu bestimmen (nK = Anzahl der Variablen pro Cluster K). Damit liegt der Aufwand zur Bestimmung der Repräsentanten des L1-Algorithmus in der gleichen Größenordnung wie beim L2-Algorithmus, bei dem der Repräsentant eines Clusters aus den Mittelwerten der Attribute gewählt wird.
Allerdings muß beachtet werden, daß beim L1-Algorithmus ein Repräsentant durch Speicheroperationen (Sortieren) ermittelt wird, während beim L2-Algorithmus dies schnelle arithmetische Operationen sind.
Durch die Aufwandsreduzierung bei der Bestimmung der Repräsentanten wird der L1-Algorithmus für die Verarbeitung großer Datenmengen praktisch relevant. Da beim L1-Algorithmus nur absolute Differenzen benutzt werden (im Gegensatz zu den quadrierten Differenzen beim L2-Algorithmus), beeinflussen Ausreißer in den Daten weniger stark das Klassifikationsergebnis. Eine Integration in die Data Mining Software Clementine über das Forschungszentrum der Daimler-Benz AG in Ulm ist vorgesehen.
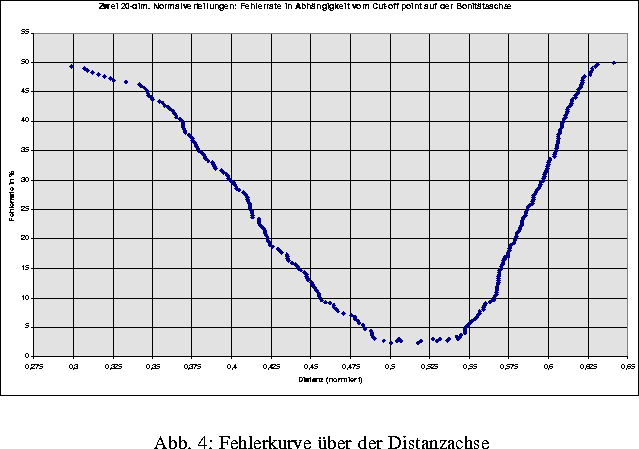
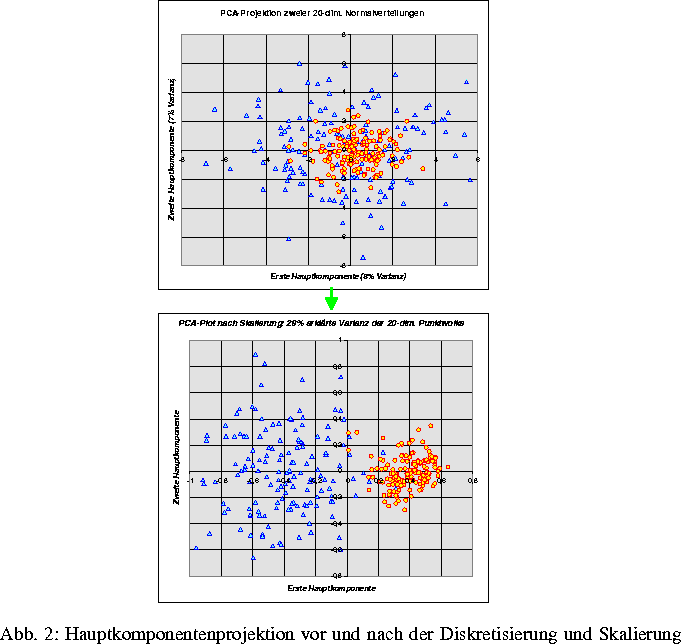
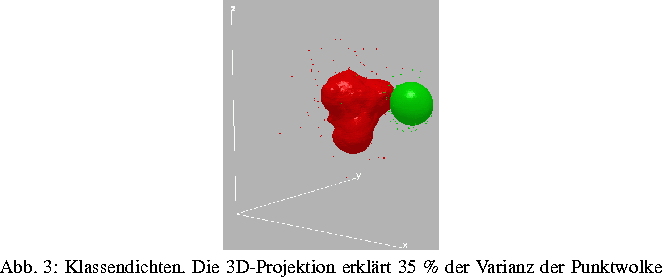
Liegen sowohl qualitative als auch quantitative Informationen über die zu klassifizierenden Objekte vor, dann kann das Modell der distanzbasierten Klassifikation z. B. nach der Diskretisierung der quantitativen Variablen angewendet werden. Ein Beispiel soll die Leistungsfähigkeit dieses Ansatzes graphisch veranschaulichen. Gegeben seien 2 Klassen mit je 150 Objekten im 20-dimensionalen Beobachtungsraum. Die Klasse 1 habe eine Normalverteilung mit dem Erwartungswert 0 und der Kovarianzmatrix I (Einheitsmatrix). Die Erwartungswerte der Klasse 2 seien nur um Wurzel von ein Zwanzigstel von 0 verschieden und die Kovarianzmatrix sei das Vierfache der Einheitsmatrix. Das ist ein bekanntes, schwieriges Klassifikationsproblem. Die Diskretisierung wurde hier durch äquidistante Einteilung in Teilintervalle durchgeführt. Die beiden Bilder der Abb. 2 zeigen die Hauptkomponentenprojektion der zufällig generierten Daten und die Hauptkomponentenprojektion dieser Daten nach erfolgter Diskretisierung und optimaler Skalierung. Abb. 3 gibt auch eine nichtparametrische 3D-Dichteschätzung der Klassen der diskretisierten und skalierten Daten wieder, was insbesondere im Falle großer Datenmengen geeigneter als der Punkteplot in Abb. 2 ist. Schließlich zeigt das letzte Bild die Fehlerkurve des Distanzklassifikators in Abhängigkeit vom Trennpunkt auf der Distanzachse.
Projektliteratur: