|
|
|
[Contents] | [Index] |
Bearbeiter: S. Jaschke , P. Mathé , G. N. Milstein , H.-J. Mucha , J. Polzehl , V. Spokoiny
Kooperation: K. Hahn (GSF-IBB, München), F. Godtliebsen (Universität Tromsø, Norwegen), G. Sebastiani (CNR/IAC Rom, Italien), F. Baumgart, T. Kaulisch (Leibniz-Institut für Neurobiologie, Magdeburg), A. Juditski (INRIA Grenoble, Frankreich), M. Hristache (Universität Rennes, Frankreich), L. Dümbgen (Medizinische Universität Lübeck), J. Horowitz (University of Iowa, USA), S. Sperlich (Universität Carlos III, Madrid, Spanien), B. Grund (University of Minnesota, USA), O. Bunke, B. Droge, W. Härdle, H. Herwartz, G. Teyssière (SFB 373, Humboldt-Universität zu Berlin), E. Heimerl (Universität Salzburg, Österreich), S. Hizir, D. Mercurio (Humboldt-Universität zu Berlin), M. Nussbaum (Cornell University, Ithaca, USA), S. V. Pereverzev (Nationale Akademie der Wissenschaften der Ukraine, Kiew), R. von Sachs, X. Baes (Universität Louvain-la-Neuve, Belgien)
Förderung: DFG, SFB 373 ,,Quantifikation und Simulation Ökonomischer Prozesse``, Humboldt-Universität zu Berlin; Volkswagen-Stiftung, RiP-Programm in Oberwolfach
Beschreibung der Forschungsarbeit: Viele interessante Anwendungen statistischer Verfahren in Ökonomie, Finanz-, Natur- und Lebenswissenschaften basieren auf komplexen hochdimensionalen Modellen und teilweise großen Datenmengen. Aufgabe der statistischen Analyse ist entweder eine qualitative Beschreibung der Daten oder eine Reduktion der Dimensionalität als Ausgangspunkt für eine weitere Analyse der Daten. Inferenz für komplexe statistische Modelle beinhaltet eine Vielzahl von Problemstellungen und Anwendungen. Diesem Schwerpunkt sind die Teilprojekte
Adaptive Verfahren der Bildverarbeitung (Bearbeiter: J. Polzehl, V. Spokoiny).
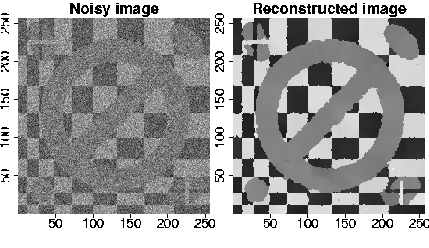
Untersuchungsmethoden in Technik, Medizin, Umweltschutz, Meteorologie und Geologie liefern vielfach Daten in Form von zwei- und dreidimensionalen Bildern. Beispiele sind u. a. Satellite Apendure Radar (SAR)-Bilder, Magnet-Resonanz (MR)-Aufnahmen oder seismische 3D-Daten in der Geologie.
Diese Bilder sind oft durch homogene Strukturen und Diskontinuitäten gekennzeichnet. Die Aufgabe, derartige Strukturen aus fehlerbehafteten (verrauschten) Bildern herauszufiltern, ist von vielen Autoren unter Nutzung verschiedener statistischer Modellansätze für verschiedene spezifische Anforderungen an das rekonstruierte Bild untersucht worden.
Ziele der Rekonstruktion sind z. B. ein Entrauschen der Bilder, das Finden homogener Bereiche und das Verstärken von Kontrasten. Das von uns entwickelte Adaptive Weights Smoothing (AWS)-Verfahren verfügt über in diesem Kontext besonders wünschenswerte Eigenschaften, wie Erhaltung von Ecken und Kanten (Kontrast) und ,,optimale`` Reduktion des Rauschens. Das Verfahren ist lokal adaptiv und nutzt die strukturelle Annahme eines lokal konstanten Regressionsmodells.
Ausgangspunkt ist das Regressionsmodell
| (1) |
 |
Die AWS zugrunde liegenden Ideen erlauben die effiziente Bearbeitung wesentlich komplizierterer Probleme. Magnet-Resonanz-Bilder (fMRI) entstehen bei Experimenten zur Bestimmung funktioneller Zentren im Gehirn. Hierbei werden Patienten einer Folge von Signalen ausgesetzt. Gleichzeitig wird eine Zeitreihe von Magnet-Resonanz-Bildern aufgezeichnet. Gegenüber der häufig verwendeten voxelweisen Analyse ermöglicht unsere Herangehensweise eine erhöhte Sensitivität durch eine zusätzliche räumlich adaptive Glättung. Die in [19] vorgeschlagene Methodik kombiniert die in [18] entwickelte Idee adaptiver Gewichte mit einer Reduktion (in Zeitrichtung) der Dimensionalität der Daten unter Erhalt der für die Problemstellung wichtigen Information.
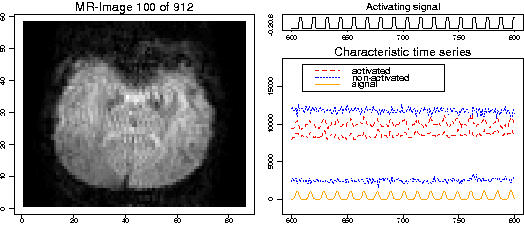 |
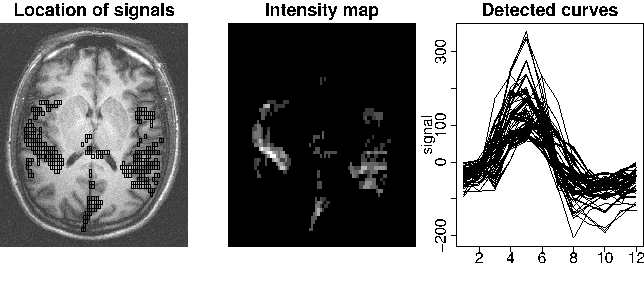
Abbildung 3 illustriert ein funktionelles Magnet-Resonanz-Experiment. Während der Patient einem Stimulus (rechts oben) ausgesetzt ist, wird eine Zeitreihe von 2D- bzw. 3D-MR-Bildern aufgezeichnet (linkes Bild). In durch das Signal aktivierten Regionen des Gehirns lassen sich induzierte Signale (BOLD-Effekt) beobachten (rechts unten).
Das in [19] vorgeschlagene räumlich adaptive Glättungsverfahren kombiniert die in [18] entwickelte Idee adaptiver Gewichte mit einer Reduktion (in Zeitrichtung) der Dimensionalität der Daten. Dies ermöglicht die effiziente Nutzung der räumlichen Ausdehnung aktivierter Regionen zur Verbesserung der Sensitivität und Spezifität der Signaldetektion.
Abbildung 4 zeigt die detektierten Signale für einen fMRI-Datensatz (Max-Planck-Institut für kognitive Neurowissenschaften, Leipzig).
Eine Anwendung der gleichen Methodik auf die Klassifikation von Gewebe anhand der zeitlichen Wirkung eines Kontrastmittels in dynamischen MR-Experimenten wird ebenfalls in [19] beschrieben.
Die Verfahren wurden im Rahmen eines Industrieprojektes zur Strukturierung geologischer Daten eingesetzt.
Effektive Dimensionsreduktion (Bearbeiter: S. Jaschke, J. Polzehl, V. Spokoiny).
Single- und Multi-Index-Modelle werden in multivariaten Problemen häufig benutzt, um das so genannte ,,curse of dimensionality``-Problem zu vermeiden. Diese Modelle verallgemeinern die klassischen linearen Modelle und können als guter Kompromiss zwischen oft zu restriktiven linearen Modellen und zu variablen rein nichtparametrischen Modellen angesehen werden. Interessierende Parameter der statistischen Analyse in diesen Modellen sind typischerweise Index-Vektoren. Derartige Indices dienen häufig zur Beschreibung makroökonomischer Daten in Ökonomie und Finanzwirtschaft. Typische Beispiele sind Börsenindices wie DAX oder Dow-Jones. Große Banken berücksichtigen 5000-10000 Finanzprodukte. Eine Dimensionsreduktion durch Zusammenfassung dieser Produkte zu Indices ermöglicht sowohl eine Risikobewertung, als auch eine Optimierung von Portfolios.
Eine neue Methode zum Schätzen des Index-Vektors im Single-Index-Modell wurde in der Gruppe vorgeschlagen [10]. Der Ansatz lässt sich als rekursive Verbesserung der klassischen Average-Derivative-Schätzer darstellen. Die theoretischen Ergebnisse zeigen, dass nach logarithmisch vielen Iterationsschritten die entsprechende Schätzung root-n-konsistent wird. Die Methode ist voll adaptiv hinsichtlich des Versuchsplans und der unbekannten Glattheitseigenschaften der Link-Funktion. Die Resultate gelten unter sehr schwachen Modellannahmen. Simulationsergebnisse zeigen eine sehr stabile und gute Leistung der Methode für hochdimensionale Zusammenhänge und moderate Stichprobenumfänge. Falls die Single-Index-Annahme nicht erfüllt ist, kann die Anwendung dieser Methode zum Informationsverlust und zu falschen Schlussfolgerungen führen. Das motivierte die weitere Entwicklung dieses Ansatzes mit dem Ziel, eine Methode anzubieten, die für breite Modellklassen erlaubt, effiziente Dimensions-Reduktion ohne signifikanten Informationsverlust durchzuführen.
Eine solche Verallgemeinerung der ursprünglichen Methode für den Fall eines Multi-Index-Modells ist in [9] entwickelt. Ein wichtiger Vorteil der neuen Methode besteht darin, dass diese keine strukturellen Voraussetzungen für das Modell benötigt. Simulationsergebnisse zeigen eine hervorragende Leistung der Methode.
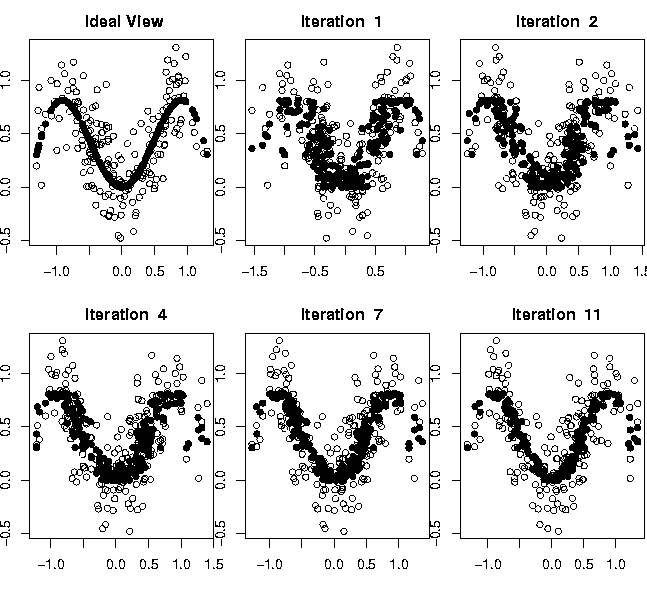
Abbildung 5
demonstriert das Ergebnis der vorgeschlagenen Methode an einem
künstlichen Beispiel für das Single-Index-Modell
![]() mit Gauß'schen Fehlern
mit Gauß'schen Fehlern
![]() .Das ,,first step``-Ergebnis entspricht der klassischen
Average-Derivative-Schätzung.
Die Verbesserung während des Iterierens ist leicht sichtbar.
.Das ,,first step``-Ergebnis entspricht der klassischen
Average-Derivative-Schätzung.
Die Verbesserung während des Iterierens ist leicht sichtbar.
 |
Statistische Inferenz für zeitinhomogene Finanzzeitreihen (Bearbeiter: J. Polzehl, V. Spokoiny).
Log-Returns ![]() erhält man als Logarithmus des Quotienten
zweier aufeinanderfolgender Werte eines zugrunde liegenden Preisprozesses.
Ein typisches Ziel der statistischen Analyse ist eine Kurzzeitvorhersage
des Volatilitätsprozesses.
Dieser Prozess wird meist mittels einer parametrischen Annahme
modelliert. Beispiele solcher Modellannahmen sind
ARCH, verallgemeinerte ARCH (GARCH) oder stochastische Volatilitätsmodelle.
Alle diese Modelle sind zeithomogen und daher nicht in der Lage,
strukturelle Änderungen des zugrunde liegenden Prozesses nachzuvollziehen.
In [7, 12] werden alternative Ansätze vorgeschlagen,
die auf der Annahme lokaler Zeithomogenität basieren und zum
Schätzen bzw. Vorhersagen der Volatilität benutzt werden können.
erhält man als Logarithmus des Quotienten
zweier aufeinanderfolgender Werte eines zugrunde liegenden Preisprozesses.
Ein typisches Ziel der statistischen Analyse ist eine Kurzzeitvorhersage
des Volatilitätsprozesses.
Dieser Prozess wird meist mittels einer parametrischen Annahme
modelliert. Beispiele solcher Modellannahmen sind
ARCH, verallgemeinerte ARCH (GARCH) oder stochastische Volatilitätsmodelle.
Alle diese Modelle sind zeithomogen und daher nicht in der Lage,
strukturelle Änderungen des zugrunde liegenden Prozesses nachzuvollziehen.
In [7, 12] werden alternative Ansätze vorgeschlagen,
die auf der Annahme lokaler Zeithomogenität basieren und zum
Schätzen bzw. Vorhersagen der Volatilität benutzt werden können.
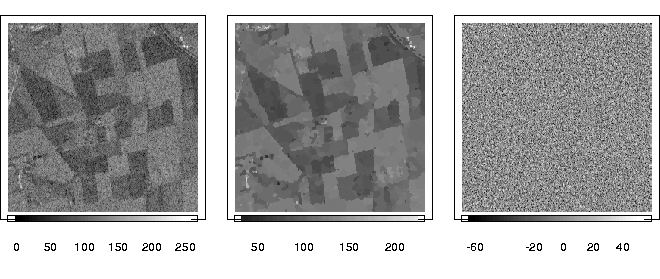
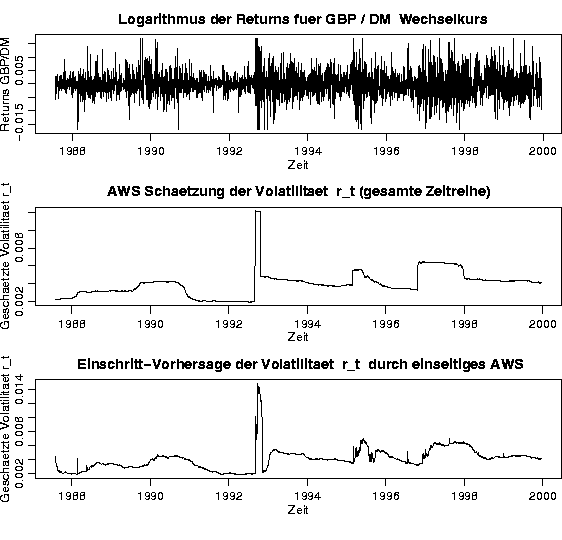
Eine Erweiterung dieses Ansatzes auf hochdimensionale Finanzdaten ist in [6] entwickelt worden. Das Verfahren beinhaltet Datentransformation, Dimensions-Reduktion und nichtparametrische Glättung.
Abbildung 6 demonstriert das Ergebnis der Methode für einen Währungsprozess.
 |
Robuste nichtparametrische Testverfahren (Bearbeiter: J. Polzehl, V. Spokoiny).
Ein wichtiges Problem der statistischen Inferenz ist das Testen einer linearen Hypothese. Es gibt eine Vielzahl von verschiedenen Methoden, die speziell für dieses Problem entwickelt worden sind. Trotzdem besteht in vielen Anwendungsgebieten Bedarf an neuen Testverfahren, die robust und adaptiv hinsichtlich Modellannahmen sind, insbesondere betrifft das die Annahmen über Fehlerverteilung. Ein perspektivischer Ansatz in dieser Richtung besteht darin, die Verteilungsquantilen statt den Erweiterungswert zu betrachten. Ein wichtiges Beispiel wird durch das Median-Regressions-Modell gegeben:
![]()
Ein adaptiver Test der linearen Hypothese
![]() gegen allgemeine nichtparametrische Alternativen
wurde in [8] entwickelt.
Die theoretischen Ergebnisse beschreiben die Güte des Tests und beweisen
seine Rate-Optimalität.
gegen allgemeine nichtparametrische Alternativen
wurde in [8] entwickelt.
Die theoretischen Ergebnisse beschreiben die Güte des Tests und beweisen
seine Rate-Optimalität.
In [5] werden Tests linearer Hypothesen in additiven Survival-Modellen entwickelt.
Clusteranalyse (Bearbeiter: H.-J. Mucha).
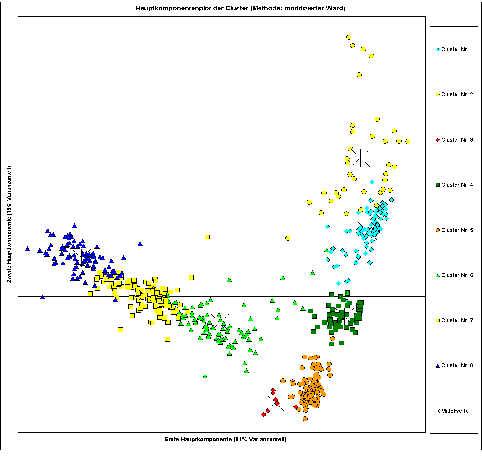
Mit der modellbasierten Clusteranalyse können viele Anwendungssituationen in guter Näherung beschrieben und somit auch die gesuchten Teilpopulationen (Cluster) erkannt und deren Parameter bestimmt werden. Die Erkennung sehr unterschiedlich großer Cluster verschiedener Form ist jedoch restriktiv bzw. problematisch immer dann, wenn es sich um hochdimensionale Probleme handelt. Wenn die Beobachtungsanzahl einiger Cluster geringer als die Variablenanzahl ist, dann reduziert sich die Modellwahl meist auf das Varianzkriterium und das logarithmierte gemittelte Varianzkriterium. Letzteres kann zur Erkennung sowohl von Clustern mit vielen Beobachtungen als auch von Clustern mit einigen wenigen Beobachtungen geeignet sein. Abbildung 7 zeigt eine Anwendung dieses Modells auf chemometrische Daten aus der Archäologie. Das kleinste Cluster enthält hier nur sieben Beobachtungen, und es werden zugleich Cluster mit mehr als hundert Beobachtungen erkannt.
Die Statistiksoftware ClusCorr98® zur automatischen Klassifikation, statistischen Datenanalyse und multivariaten Visualisierung wurde um modellbasierte Verfahren erweitert. ClusCorr98® ist in Visual Basic for Applications geschrieben und unter Windows oder Windows NT lauffähig. Im Industrieprojekt mit der Firma EEG (Erdgas Erdöl GmbH Berlin) wurden die in der Statistiksoftware verfügbaren adaptiven Methoden der partitionierenden Clusteranalyse zur Erkundung von Rohstofflagerstätten eingesetzt.
Numerik statistischer schlecht gestellter Probleme (Bearbeiter: P. Mathé).
Beim Entwurf numerischer Verfahren zur Lösung konkreter Probleme ist
es wichtig, gegebene
a priori-Informationen effektiv (optimal)
zu nutzen. Dieser Aspekt hat Bedeutung sowohl bei der Festlegung von
Diskretisierungen, als auch bei der Wahl geeigneter Algorithmen bei
gegebener Diskretisierung, da sich hier entscheidet, ob mit den
diskreten Daten effizient gearbeitet wird oder ob ein unnötiger ,,
computational overhead`` erzeugt wird.
In Zusammenarbeit mit S. V. Pereverzev wird dieser Problemkreis anhand schlecht gestellter statistischer Probleme
![]()
![]()
Die Untersuchungen konzentrierten sich auf das Problem, Funktionale von Lösungen obiger Gleichungen approximativ zu berechnen. Möglich ist hierbei der Zugang über die approximative Bestimmung der gesamten Näherungslösung und die nachherige Anwendung des Funktionals, die Solution-Functional Strategy, aber auch die direkte Bestimmung unmittelbar aus den Daten, die Data-Functional Strategy, siehe [1, 3]. Die Erkenntnisse aus den von der DFG geförderten Untersuchungen können wie folgt zusammengefasst werden.
Herr Pereverzev hat die Ergebnisse auf der Konferenz ,,Mathematical Statistics`` (Marseille-Luminy, Frankreich, 11.-15. Dezember 2000) vorgestellt.
Statistische und Monte-Carlo-Methoden für die Bewertung der Markov'schen Übergangswahrscheinlichkeitsdichte (Bearbeiter: G. N. Milstein, J. Schoenmakers, V. Spokoiny).
Die bekannte wahrscheinlichkeitstheoretische Repräsentation von Lösungen linearer partieller Differentialgleichungen und numerische Integration stochastischer Differentialgleichungen werden gemeinsam mit Ideen der Mathematischen Statistik zum Schätzen der Markov'schen Übergangsdichte von Diffusionsprozessen, siehe [14], genutzt. Ein weiteres Problem der statistischen Schätztheorie wird in [13] betrachtet.
Projektliteratur:
|
|
|
[Contents] | [Index] |