


Bearbeiter: H.-J. Mucha
Kooperation: W. Härdle, Institut für Statistik und Ökonometrie, Humboldt-Universität
Beschreibung der Forschungsarbeit:
Im Rahmen der computerorientierten Statistik wurden die Arbeiten zur Entwicklung neuer adaptiver Clusteranalysemethoden fortgesetzt. Die adaptiven Clusteranalysetechniken gewinnen insbesondere im Hinblick auf die Eröffnung neuer Möglichkeiten zur multivariaten grafischen Darstellung sehr an Bedeutung. Gemeinsame Grundlage sind die in der adaptiven Clusteranalyse berechneten gewichteten Distanzmaße. Beispielsweise kann die Veränderung des Betrachtungsraumes in der adaptiven Clusteranalyse (infolge der iterativen Änderung des zugrundeliegenden adaptiven Distanzmaßes) als Bildfolge dargestellt werden, die sukzessive die verborgenen Datenstrukturen ähnlich einem Wolkenbildungsprozeß sichtbar werden läßt. Es wurden entsprechende Werbematerialien gestaltet.

Es wurden Simulationsstudien zur Bewertung der Stabilität neuer Verfahren durchgeführt, und die Eignung adaptiver Clusteranalysetechniken in realen Anwendungsbeispielen wurde untersucht.
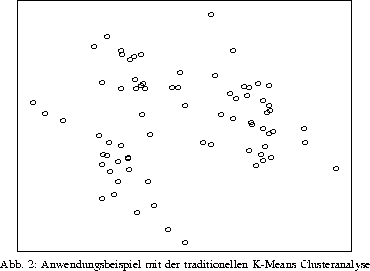
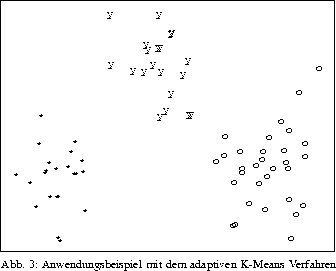
Die Integration der Clusteranalyse-Software ClusCorr, die der 1992 erschienenen Monographie ``Clusteranalyse mit Mikrocomputern`` zugrundeliegt, in das größere Statistikpaket XploRe (W. Härdle, Humboldt-Universität) konnte in mehreren Vorträgen und Publikationen dokumentiert werden. Insbesondere zu den Wirtschaftswissenschaften ist eine praxisorientierte interdisziplinäre Kooperation realisiert worden. Ausdruck dessen ist die aktive Mitarbeit im SFB 373 auf dem Gebiet der statistischen Cluster- und Datenanalyse und deren Praxiseinsatz zur Lösung ökonometrischer Fragestellungen. Hierbei können einfache adaptive Modelle der Cluster- und Hauptkomponentenanalyse zum Verständnis hochdimensionaler Zusammenhänge beitragen. Die Interpretation der multivariaten Grafiken und Klassifikationsresultate in bezug auf die gemessenen Originalvariablen kann aufgrund der Einfachheit der adaptiven Modelle vom Wirtschaftswissenschaftler selbst vorgenommen werden. Die Abbildung zeigt ein Anwendungsbeispiel zur Untersuchung der Kreditwürdigkeit von Kunden des Versandhauses Quelle. Andere Anwendungen wurden zur Marktsegmentierung und zum Branchenvergleich durchgeführt. In einem Anwendungsbeispiel aus der Biologie wird das adaptive K-Means Verfahren veranschaulicht. Die Erkennung von 3 Klassen (Spezies einer Tierart) in den abgebildeten Daten (Hauptkomponentenplot basierend auf der Korrelationsmatrix der 6 Originalvariablen) mit der K-Means Clusteranalyse gelingt nicht; die Fehlerrate ist hoch. Das adaptive K-Means Verfahren trennt die Klassen fehlerfrei. Das Ergebnis kann durch die Hauptkomponentenanalyse unter Verwendung der berechneten adaptiven Variablengewichte visualisiert werden.
Wesentliche Fortschritte konnten beim Manuskript zum geplanten Buch ,,Clustering Techniques`` erzielt werden.
Förderung: DFG, SFB 373 ,,Quantifikation und Simulation ökonomischer Prozesse``
Projektliteratur: