
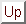



Bearbeiter: H.-J. Mucha, R. Siegmund-Schultze (FG 7), G. Reinhardt, J. Fuhrmann (FG 3)
Kooperation: G. Nakhaeizadeh, U. Grimmer, H. Kauderer (Forschungszentrum Daimler Benz AG Ulm), K. Dübon (Mercedes Benz AG Stuttgart)
Förderung: Daimler Benz AG Ulm
Beschreibung der Forschungsarbeit:
Seit 1995 wird die Windows-Software ClusCorr zur Clusteranalyse, Klassifikation und multivariaten grafischen Darstellung umfangreicher und hochdimensionaler Datenmengen entwickelt. Das Verfahrensinventar wird ständig verbessert und erweitert. So wurden z. B. Verfahren zur nichtparametrischen Dichteschätzung für den ein- und zweidimensionalen Fall aufgenommen. Für umfangreiche Datenmengen wird die WARPing-Technik zur zeitlich effektiven Dichteschätzung als Standardvariante empfohlen.
ClusCorr unter Microsoft EXCEL wurde auf der CeBIT 96 in Hannover und auf der Innovationsmesse in Leipzig vorgestellt. Hierbei wurde einer größeren Anzahl von potentiellen Anwendern und Interessenten statistische Beratung gegeben. ClusCorr zielt auf einen breiten Anwenderkreis, der theoretisch und praktisch in Lehre, Ausbildung, Forschung und Wirtschaft mit statistischer Datenanalyse befaßt ist. Den Schwerpunkt dieser Software bilden Clusteranalyse-Methoden, die auf adaptiven Distanzen beruhen. In hochdimensionalen Merkmalsräumen können oft erst durch Benutzung adaptiver Distanzen Strukturen (Klassen, Hierarchien) erkannt und mit multivariaten Projektionsmethoden visualisiert werden.
Auf der Konferenz IFCS-96 (Fifth Conference of the International Federation of Classification Societies) wurde ein Vortrag über adaptive Klassifikation gehalten und eine Software-Demonstration zu ClusCorr durchgeführt. Im Juni 1996 wurde auf Einladung des Forschungszentrums der Daimler Benz AG ein Workshop zur Clusteranalyse veranstaltet. Über den aktuellen Entwicklungsstand von ClusCorr wurde auch auf der vom WIAS organisierten Herbsttagung der Gesellschaft für Klassifikation vorgetragen. Mit der Statistik-Software ClusCorr waren neben der Beratungstätigkeit auch Einnahmen aus Verkäufen verbunden.
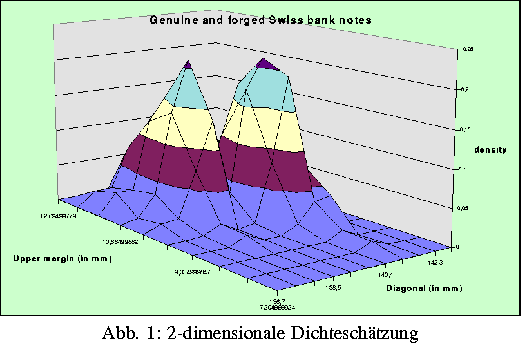
Ausgangspunkt des Teilprojektes Data Mining Software Clementine war die erfolgreiche Anwendung adaptiver Clusteranalyse-Methoden zur Lösung von Klassifikationsproblemen und als vorbereitende statistische Datenanalyse für Machine Learning / Knowledge Discovery Verfahren aus dem Bereich Credit Scoring und Data Mining. Die Ergebnisse adaptiver distanzbasierter Modelle können z. B. in neuronale Netze eingespeist werden. Ein (sehr willkommener) Nebeneffekt ist hierbei die Zeitreduzierung in der Lernphase des neuronalen Netzes um ein Vielfaches. Der lokal adaptive Distanzzugang bietet zusätzlich die Möglichkeit, hochdimensionale alphanumerische und numerische Daten graphisch darzustellen.
Während des ersten Arbeitsaufenthalts im Forschungszentrum der Daimler
Benz AG in Ulm im September wurde mit der Realisierung des
Clusteranalyse-Projekts
für die Data Mining Software Clementine begonnen. Die Verarbeitung
von Massendaten erfordert jedoch sehr effiziente numerische Algorithmen
und eine aufwendige Grafik. Aus diesem Grunde begann eine intensive
abteilungsübergreifende Zusammenarbeit im WIAS. Erste vielbeachtete
Ergebnisse konnten auf der Herbsttagung der Gesellschaft
für Klassifikation,
die im WIAS stattfand, vorgestellt werden. Daraufhin entwickelte sich
eine breitere Kooperation
mit dem Forschungszentrum der Daimler Benz AG. Auf einem weiteren
Arbeitstreffen
in Ulm wurden Vorträge gehalten und eine erste Betaversion des
gesamten Projekts realisiert, das die Portierung der adaptiven
Clusteranalyse mit multivariater Grafik auf der Grundlage der
OpenGL-basierten Toolbox gltools
des WIAS, S.
 ,
in die Data Mining Software Clementine vorsieht.
Die wissenschaftliche Zusammenarbeit konzentriert sich insbesondere auf
die Anpassung
adaptiver Clusteranalyse-Modelle an die Erfordernisse der statistischen
Analyse von
Massendaten und auf die Implementierung und Nutzung effektiver
numerischer Algorithmen zur
Lösung von Approximations- und Optimierungsproblemen in
Klassifikationsmodellen und zur graphischen Ergebnisausgabe.
,
in die Data Mining Software Clementine vorsieht.
Die wissenschaftliche Zusammenarbeit konzentriert sich insbesondere auf
die Anpassung
adaptiver Clusteranalyse-Modelle an die Erfordernisse der statistischen
Analyse von
Massendaten und auf die Implementierung und Nutzung effektiver
numerischer Algorithmen zur
Lösung von Approximations- und Optimierungsproblemen in
Klassifikationsmodellen und zur graphischen Ergebnisausgabe.
Das Teilprojekt Distanzbasiertes Kredit Scoring entstand 1995 auf Initiative von Herrn K. Dübon (Mercedes Benz AG Stuttgart, Abt. Finanzcontrolling). Ausgangspunkt war die Fragestellung, ob (adaptive) Clusteranalyse-Methoden für Klassifikationsaufgaben aus dem Bereich Kredit Scoring und Data Mining als Alternative zu Maschine Learning / Knowledge Discovery- Verfahren eingesetzt werden können oder/und als ,,sinnvolle`` vorbereitende Datenanalyseschritte für die obengenannten Verfahren geeignet sind.
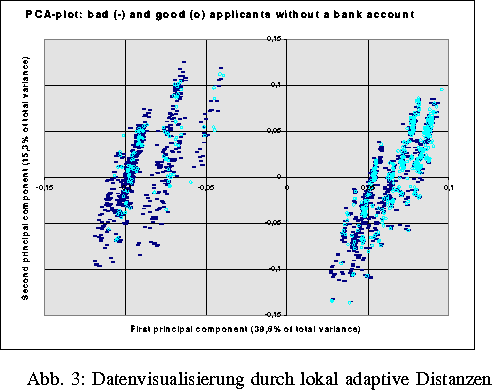
Hierbei liegt der Untersuchungsschwerpunkt auf der Verarbeitung von qualitativen (kategorialen) und quantitativen (ordinalen, metrischen) Informationen mit dem Ziel, möglichst optimale Entscheidungsregeln hinsichtlich der Fehlerrate abzuleiten. Zum Beispiel ist über die Annahme oder Ablehnung beantragter Kredite mit minimaler Fehlerrate zu entscheiden. Die Aktivitäten werden in Zusammenarbeit mit der Gruppe Maschinelles Lernen (Daimler Benz AG) weitergeführt. Der Hauptschwerpunkt der wissenschaftlichen Zusammenarbeit verlagert sich zunehmend auf die Untersuchung und Berücksichtigung dynamischer Aspekte sowie auf Stabilitätsuntersuchungen durch Simulationsstudien.
Projektliteratur: